Real and Simulated Profiles
In the previous section, we discussed the Ballot class. It was very
flexible, allowing for many possible rankings (beyond full linear
rankings) to be stored. By the end of this section, you should be able
to read and clean ballots from real-world voting records, generate
ballots using a variety of models, and understand the candidate simplex.
Real-World Data
We will use the 2013 Minneapolis mayoral election as our first example. This election had 35 candidates running for one seat, and used a single-winner IRV election to choose the winner. Voters were allowed to rank their top three candidates.
Let’s load in the cast vote record (CVR) from the election, which we have stored in the VoteKit GitHub repository. Please download the file and place it in your working directory (the same folder as your code). The file can be found here.
First we load the appropriate modules.
from votekit.cvr_loaders import load_ranking_csv
from votekit.elections import IRV
from votekit.cleaning import remove_cand_rank_profile, remove_repeat_cands_rank_profile, condense_rank_profile
Next we’ll use the load_ranking_csv function to load the data. The
data should be a csv file, where each row is a ballot, and there is a
column for every position—i.e., a first-place vote column, a
second-place vote column, and so on. We need to specify which are the
ranking columns.
The load_ranking_csv function has some optional parameters; whether
there is a weight column, some choice of delimiters (besides the
standard, which is a comma), a voter ID column, a weight column, and a
header. It will return a PreferenceProfile object. The function also
prints the profile by default, so that you can quickly spot check that
it was loaded correctly. Often the easiest place to catch loading errors
is in the candidate list.
Note for previous users: as of VoteKit 3.3.0, the function load_csv
is being deprecated in favor of load_ranking_csv.
minneapolis_profile = load_ranking_csv("mn_2013_cast_vote_record.csv", rank_cols= [0,1,2])
RankProfile
Maximum ranking length: 3
Candidates: ('rank3', 'JEFFREY ALAN WAGNER', 'TROY BENJEGERDES', 'CYD GORMAN', 'JAMES EVERETT', 'MARK V ANDERSON', 'NEAL BAXTER', 'STEPHANIE WOODRUFF', 'CAM WINTON', 'CAPTAIN JACK SPARROW', 'CHRISTOPHER CLARK', 'OLE SAVIOR', 'JAMES "JIMMY" L. STROUD, JR.', 'JAYMIE KELLY', 'GREGG A. IVERSON', 'undervote', 'MERRILL ANDERSON', 'ALICIA K. BENNETT', 'BOB FINE', 'RAHN V. WORKCUFF', 'BILL KAHN', 'EDMUND BERNARD BRUYERE', 'JOSHUA REA', 'MIKE GOULD', 'BOB "AGAIN" CARNEY JR', 'MARK ANDREW', 'KURTIS W. HANNA', 'BETSY HODGES', 'JOHN LESLIE HARTWIG', 'JACKIE CHERRYHOMES', 'overvote', 'DAN COHEN', 'DON SAMUELS', 'DOUG MANN', 'CHRISTOPHER ROBIN ZIMMERMAN', 'rank1', 'ABDUL M RAHAMAN "THE ROCK"', 'TONY LANE', 'Rank2', 'UWI', 'JOHN CHARLES WILSON')
Candidates who received votes: ('rank3', 'JEFFREY ALAN WAGNER', 'TROY BENJEGERDES', 'CYD GORMAN', 'JAMES EVERETT', 'MARK V ANDERSON', 'NEAL BAXTER', 'STEPHANIE WOODRUFF', 'CAM WINTON', 'CAPTAIN JACK SPARROW', 'CHRISTOPHER CLARK', 'OLE SAVIOR', 'JAMES "JIMMY" L. STROUD, JR.', 'JAYMIE KELLY', 'GREGG A. IVERSON', 'undervote', 'MERRILL ANDERSON', 'ALICIA K. BENNETT', 'BOB FINE', 'RAHN V. WORKCUFF', 'BILL KAHN', 'EDMUND BERNARD BRUYERE', 'JOSHUA REA', 'MIKE GOULD', 'BOB "AGAIN" CARNEY JR', 'MARK ANDREW', 'KURTIS W. HANNA', 'BETSY HODGES', 'JOHN LESLIE HARTWIG', 'JACKIE CHERRYHOMES', 'overvote', 'DAN COHEN', 'DON SAMUELS', 'DOUG MANN', 'CHRISTOPHER ROBIN ZIMMERMAN', 'rank1', 'ABDUL M RAHAMAN "THE ROCK"', 'TONY LANE', 'Rank2', 'UWI', 'JOHN CHARLES WILSON')
Total number of Ballot objects: 80102
Total weight of Ballot objects: 80102.0
Ah, check out the candidate list above. There are some incorrect
candidate names, like “rank1” and “Rank2”. If you go inspect the csv
file, you’ll see that these are the names of the header row. We forgot
to include the header as a parameter to load_ranking_csv, which by
default assumes there is no header.
minneapolis_profile = load_ranking_csv("mn_2013_cast_vote_record.csv", rank_cols= [0,1,2], header_row = 0)
RankProfile
Maximum ranking length: 3
Candidates: ('JEFFREY ALAN WAGNER', 'TROY BENJEGERDES', 'CYD GORMAN', 'JAMES EVERETT', 'MARK V ANDERSON', 'NEAL BAXTER', 'STEPHANIE WOODRUFF', 'CAM WINTON', 'CAPTAIN JACK SPARROW', 'CHRISTOPHER CLARK', 'OLE SAVIOR', 'JAMES "JIMMY" L. STROUD, JR.', 'JAYMIE KELLY', 'GREGG A. IVERSON', 'undervote', 'MERRILL ANDERSON', 'ALICIA K. BENNETT', 'BOB FINE', 'RAHN V. WORKCUFF', 'BILL KAHN', 'EDMUND BERNARD BRUYERE', 'JOSHUA REA', 'MIKE GOULD', 'BOB "AGAIN" CARNEY JR', 'MARK ANDREW', 'KURTIS W. HANNA', 'BETSY HODGES', 'JOHN LESLIE HARTWIG', 'JACKIE CHERRYHOMES', 'overvote', 'DAN COHEN', 'DON SAMUELS', 'DOUG MANN', 'CHRISTOPHER ROBIN ZIMMERMAN', 'ABDUL M RAHAMAN "THE ROCK"', 'TONY LANE', 'UWI', 'JOHN CHARLES WILSON')
Candidates who received votes: ('JEFFREY ALAN WAGNER', 'TROY BENJEGERDES', 'CYD GORMAN', 'JAMES EVERETT', 'MARK V ANDERSON', 'NEAL BAXTER', 'STEPHANIE WOODRUFF', 'CAM WINTON', 'CAPTAIN JACK SPARROW', 'CHRISTOPHER CLARK', 'OLE SAVIOR', 'JAMES "JIMMY" L. STROUD, JR.', 'JAYMIE KELLY', 'GREGG A. IVERSON', 'undervote', 'MERRILL ANDERSON', 'ALICIA K. BENNETT', 'BOB FINE', 'RAHN V. WORKCUFF', 'BILL KAHN', 'EDMUND BERNARD BRUYERE', 'JOSHUA REA', 'MIKE GOULD', 'BOB "AGAIN" CARNEY JR', 'MARK ANDREW', 'KURTIS W. HANNA', 'BETSY HODGES', 'JOHN LESLIE HARTWIG', 'JACKIE CHERRYHOMES', 'overvote', 'DAN COHEN', 'DON SAMUELS', 'DOUG MANN', 'CHRISTOPHER ROBIN ZIMMERMAN', 'ABDUL M RAHAMAN "THE ROCK"', 'TONY LANE', 'UWI', 'JOHN CHARLES WILSON')
Total number of Ballot objects: 80101
Total weight of Ballot objects: 80101.0
Let’s explore the profile using some of the tools we learned in the previous notebook.
print("The list of candidates is")
for candidate in sorted(minneapolis_profile.candidates):
print(f"\t{candidate}")
print(f"There are {len(minneapolis_profile.candidates)} candidates.")
The list of candidates is
ABDUL M RAHAMAN "THE ROCK"
ALICIA K. BENNETT
BETSY HODGES
BILL KAHN
BOB "AGAIN" CARNEY JR
BOB FINE
CAM WINTON
CAPTAIN JACK SPARROW
CHRISTOPHER CLARK
CHRISTOPHER ROBIN ZIMMERMAN
CYD GORMAN
DAN COHEN
DON SAMUELS
DOUG MANN
EDMUND BERNARD BRUYERE
GREGG A. IVERSON
JACKIE CHERRYHOMES
JAMES "JIMMY" L. STROUD, JR.
JAMES EVERETT
JAYMIE KELLY
JEFFREY ALAN WAGNER
JOHN CHARLES WILSON
JOHN LESLIE HARTWIG
JOSHUA REA
KURTIS W. HANNA
MARK ANDREW
MARK V ANDERSON
MERRILL ANDERSON
MIKE GOULD
NEAL BAXTER
OLE SAVIOR
RAHN V. WORKCUFF
STEPHANIE WOODRUFF
TONY LANE
TROY BENJEGERDES
UWI
overvote
undervote
There are 38 candidates.
There are candidates called ‘undervote’, ‘overvote’, and ‘UWI’. This cast vote record was already cleaned by the City of Minneapolis, and they chose this way of parsing the ballots: ‘undervote’ indicates that the voter left a position unfilled, such as by having no candidate listed in second place. The ‘overvote’ notation arises when a voter puts two candidates in one position, like by putting Hodges and Samuels both in first place. Unfortunately this way of storing the profile means we have lost any knowledge of the voter intent (which was probably to indicate equal preference). ‘UWI’ stands for unregistered write-in.
This reminds us that it is really important to think carefully about how
we want to handle cleaning ballots, as some storage methods are
efficient but lossy. For now, let’s assume that we want to further clean
the ballots, discarding ‘undervote’, ‘overvote’, and ‘UWI’ as
candidates. The function remove_cand_rank_profile will do this for
us once we specify which candidates to remove. If a ballot was “A B
undervote”, it will become “A B ()”. If a ballot was “A UWI B” it will
now be “A () B”. Many other cleaning options are reasonable.
We will address the removal of “()” later on.
print("There were", len(minneapolis_profile.candidates), "candidates\n")
clean_profile = remove_cand_rank_profile(["undervote", "overvote", "UWI"], minneapolis_profile)
print(clean_profile.candidates)
print("\nThere are now", len(clean_profile.candidates), "candidates.\n")
print(clean_profile)
There were 38 candidates
('JEFFREY ALAN WAGNER', 'TROY BENJEGERDES', 'CYD GORMAN', 'JAMES EVERETT', 'MARK V ANDERSON', 'NEAL BAXTER', 'STEPHANIE WOODRUFF', 'CAM WINTON', 'CAPTAIN JACK SPARROW', 'CHRISTOPHER CLARK', 'OLE SAVIOR', 'JAMES "JIMMY" L. STROUD, JR.', 'JAYMIE KELLY', 'GREGG A. IVERSON', 'MERRILL ANDERSON', 'ALICIA K. BENNETT', 'BOB FINE', 'RAHN V. WORKCUFF', 'BILL KAHN', 'EDMUND BERNARD BRUYERE', 'JOSHUA REA', 'MIKE GOULD', 'BOB "AGAIN" CARNEY JR', 'MARK ANDREW', 'KURTIS W. HANNA', 'JOHN LESLIE HARTWIG', 'JACKIE CHERRYHOMES', 'DAN COHEN', 'DON SAMUELS', 'DOUG MANN', 'CHRISTOPHER ROBIN ZIMMERMAN', 'ABDUL M RAHAMAN "THE ROCK"', 'TONY LANE', 'BETSY HODGES', 'JOHN CHARLES WILSON')
There are now 35 candidates.
Profile has been cleaned
RankProfile
Maximum ranking length: 3
Candidates: ('JEFFREY ALAN WAGNER', 'TROY BENJEGERDES', 'CYD GORMAN', 'JAMES EVERETT', 'MARK V ANDERSON', 'NEAL BAXTER', 'STEPHANIE WOODRUFF', 'CAM WINTON', 'CAPTAIN JACK SPARROW', 'CHRISTOPHER CLARK', 'OLE SAVIOR', 'JAMES "JIMMY" L. STROUD, JR.', 'JAYMIE KELLY', 'GREGG A. IVERSON', 'MERRILL ANDERSON', 'ALICIA K. BENNETT', 'BOB FINE', 'RAHN V. WORKCUFF', 'BILL KAHN', 'EDMUND BERNARD BRUYERE', 'JOSHUA REA', 'MIKE GOULD', 'BOB "AGAIN" CARNEY JR', 'MARK ANDREW', 'KURTIS W. HANNA', 'JOHN LESLIE HARTWIG', 'JACKIE CHERRYHOMES', 'DAN COHEN', 'DON SAMUELS', 'DOUG MANN', 'CHRISTOPHER ROBIN ZIMMERMAN', 'ABDUL M RAHAMAN "THE ROCK"', 'TONY LANE', 'BETSY HODGES', 'JOHN CHARLES WILSON')
Candidates who received votes: ('JEFFREY ALAN WAGNER', 'TROY BENJEGERDES', 'CYD GORMAN', 'JAMES EVERETT', 'MARK V ANDERSON', 'NEAL BAXTER', 'STEPHANIE WOODRUFF', 'CAM WINTON', 'CAPTAIN JACK SPARROW', 'CHRISTOPHER CLARK', 'OLE SAVIOR', 'JAMES "JIMMY" L. STROUD, JR.', 'JAYMIE KELLY', 'GREGG A. IVERSON', 'MERRILL ANDERSON', 'ALICIA K. BENNETT', 'BOB FINE', 'RAHN V. WORKCUFF', 'BILL KAHN', 'EDMUND BERNARD BRUYERE', 'JOSHUA REA', 'MIKE GOULD', 'BOB "AGAIN" CARNEY JR', 'MARK ANDREW', 'KURTIS W. HANNA', 'BETSY HODGES', 'JOHN LESLIE HARTWIG', 'JACKIE CHERRYHOMES', 'DON SAMUELS', 'DOUG MANN', 'CHRISTOPHER ROBIN ZIMMERMAN', 'ABDUL M RAHAMAN "THE ROCK"', 'TONY LANE', 'DAN COHEN', 'JOHN CHARLES WILSON')
Total number of Ballot objects: 80101
Total weight of Ballot objects: 80101.0
Things look a bit cleaner; all three of the non-candidate strings have been removed. Note that the order of candidates is not very meaningful; it’s just the order in which the names occurred in the input data.
We also need to use remove_repeat_cands_rank_profile, which cleans
ballots that have the same candidate appear in multiple positions. It
keeps the first instance and removes any after that. For example, the
ballot “A B A” would become “A B ()”, while the ballot “A A B” would
become “A () B”.
clean_profile = remove_repeat_cands_rank_profile(clean_profile)
The removal of candidates and repeated candidates has caused some of our ballots to have empty ranking positions. The final step of cleaning is to condense the ballots, moving up any lower ranked candidates where an empty ranking position is. Thus the ballot “A () B” becomes “A B” while the ballot “A B ()” also becomes “A B”.
clean_profile = condense_rank_profile(clean_profile)
Briefly, let’s run the same kind of election type that was conducted in 2013 to verify we get the same outcome as the city announced. The city used IRV elections (which are equivalent to STV for one seat). Let’s check it out.
# an IRV election for one seat
minn_election = IRV(profile=clean_profile)
print(minn_election)
Status Round
BETSY HODGES Elected 35
MARK ANDREW Eliminated 34
DON SAMUELS Eliminated 33
CAM WINTON Eliminated 32
JACKIE CHERRYHOMES Eliminated 31
BOB FINE Eliminated 30
DAN COHEN Eliminated 29
STEPHANIE WOODRUFF Eliminated 28
MARK V ANDERSON Eliminated 27
DOUG MANN Eliminated 26
OLE SAVIOR Eliminated 25
JAMES EVERETT Eliminated 24
ALICIA K. BENNETT Eliminated 23
ABDUL M RAHAMAN "THE ROCK" Eliminated 22
CAPTAIN JACK SPARROW Eliminated 21
CHRISTOPHER CLARK Eliminated 20
TONY LANE Eliminated 19
JAYMIE KELLY Eliminated 18
MIKE GOULD Eliminated 17
KURTIS W. HANNA Eliminated 16
CHRISTOPHER ROBIN ZIMMERMAN Eliminated 15
JEFFREY ALAN WAGNER Eliminated 14
NEAL BAXTER Eliminated 13
TROY BENJEGERDES Eliminated 12
GREGG A. IVERSON Eliminated 11
MERRILL ANDERSON Eliminated 10
JOSHUA REA Eliminated 9
BILL KAHN Eliminated 8
JOHN LESLIE HARTWIG Eliminated 7
EDMUND BERNARD BRUYERE Eliminated 6
JAMES "JIMMY" L. STROUD, JR. Eliminated 5
RAHN V. WORKCUFF Eliminated 4
BOB "AGAIN" CARNEY JR Eliminated 3
CYD GORMAN Eliminated 2
JOHN CHARLES WILSON Eliminated 1
If you’re so moved, take a moment to go verify that we got the same order of elimination and the same winning candidate as in the official election.
Well that was simple! One takeaway: cleaning your data is a crucial step, and how you clean your data depends on your own context. This is why VoteKit provides helper functions to clean ballots, but it does not automatically apply them.
Simulated voting with ballot generators
If we want to get a large sample of ballots without using real-world data, we can use a variety of ballot generators included in VoteKit.
Bradley-Terry
The slate-Bradley-Terry model (s-BT) uses the same set of input
parameters as s-PL: slate_to_candidates, bloc_voter_prop,
cohesion_parameters, and pref_intervals_by_bloc. In fact, there
are many models that use the same inpuit parameters. We refer to these
as BlocSlate models because they require knowledge of a bloc/slate
structure to create. We have made a class BlocSlateConfig that
handles validating these parameters.
We call s-BT the deliberative voter model because part of the generation process involves making all pairwise comparisons between candidates on the ballot. A more detailed discussion can be found in our social choice documentation.
import votekit.ballot_generator as bg
from votekit import PreferenceInterval
bloc_proportions = {"Alpha": 0.8, "Xenon": 0.2}
slate_to_candidates = {"Alpha": ["A", "B"], "Xenon": ["X", "Y"]}
# note that we include candidates with 0 support, and that our preference intervals
# will automatically rescale to sum to 1
preference_mapping = {
"Alpha": {
"Alpha": PreferenceInterval({"A": 0.8, "B": 0.15}),
"Xenon": PreferenceInterval({"X": 0, "Y": 0.05}),
},
"Xenon": {
"Alpha": PreferenceInterval({"A": 0.05, "B": 0.05}),
"Xenon": PreferenceInterval({"X": 0.45, "Y": 0.45}),
},
}
# assume that each bloc is 90% cohesive
cohesion_mapping = {
"Alpha": {"Alpha": 0.9, "Xenon": 0.1},
"Xenon": {"Xenon": 0.9, "Alpha": 0.1},
}
config = bg.BlocSlateConfig(n_voters=100,
bloc_proportions=bloc_proportions,
cohesion_mapping=cohesion_mapping,
preference_mapping=preference_mapping,
slate_to_candidates=slate_to_candidates)
profile = bg.slate_bt_profile_generator(config)
print(profile.df)
Ranking_1 Ranking_2 Ranking_3 Ranking_4 Weight Voter Set
Ballot Index
0 (A) (B) (Y) (X) 69.0 {}
1 (A) (Y) (B) (X) 10.0 {}
2 (Y) (A) (B) (X) 1.0 {}
3 (Y) (A) (X) (B) 6.0 {}
4 (Y) (X) (A) (B) 14.0 {}
config.n_voters = 100000
mcmc_profile = bg.slate_bt_profile_generator_using_mcmc(config)
print(profile.df)
Ranking_1 Ranking_2 Ranking_3 Ranking_4 Weight Voter Set
Ballot Index
0 (A) (B) (Y) (X) 69.0 {}
1 (A) (Y) (B) (X) 10.0 {}
2 (Y) (A) (B) (X) 1.0 {}
3 (Y) (A) (X) (B) 6.0 {}
4 (Y) (X) (A) (B) 14.0 {}
Generating Preference Intervals from Hyperparameters
Now that we have seen a few ballot generators, we can introduce the candidate simplex and the Dirichlet distribution.
We saw that you can initialize the Plackett-Luce model and the Bradley-Terry model from a preference interval (or multiple ones if you have different voting blocs). Recall, a preference interval stores a voter’s preference for candidates as a vector of non-negative values that sum to 1. Other models that rely on preference intervals include the Cambridge Sampler (CS). There is a nice geometric representation of preference intervals via the candidate simplex.
Candidate Simplex
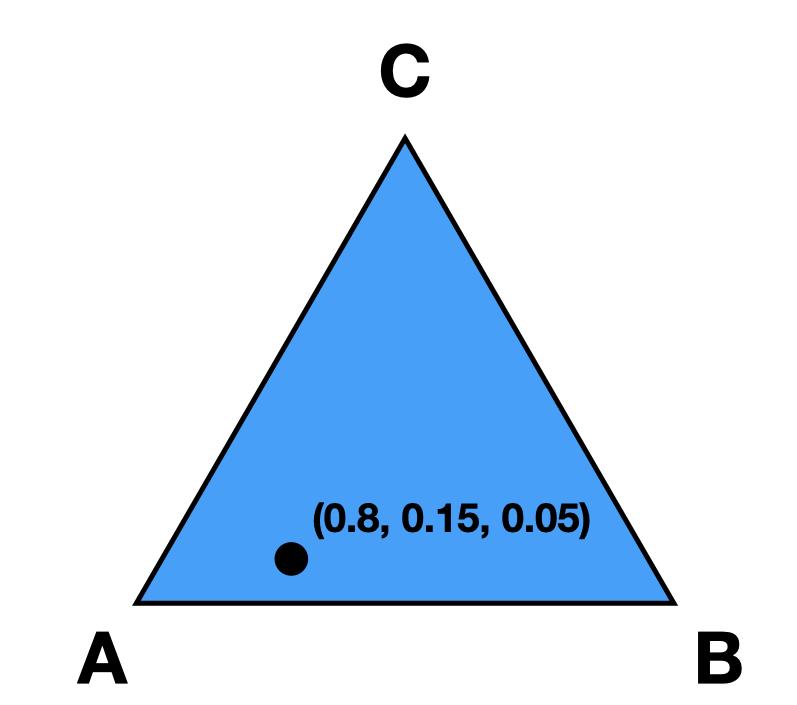
Informally, the candidate simplex is a geometric representation of the space of preference intervals. With two candidates, it is an interval; with three candidates, it is a triangle; with four, a tetrahedron; and so on getting harder to visualize as the dimension goes up.
This will be easiest to visualize with three candidates \(A,B,C\). Then there is a one-to-one correspondence between positions in the triangle and what are called convex combinations of the extreme points. For instance, \(.8A+.15B+.05C\) is a weighted average of those points giving 80% of the weight to \(A\), 15% to \(B\), and 5% to \(C\). The result is a point that is closest to \(A\), as seen in the picture.
Those coefficients, which sum to 1, become the lengths of the candidate’s sub-intervals. So this lets us see the simplex as the space of all preference intervals.
png
Dirichlet Distribution
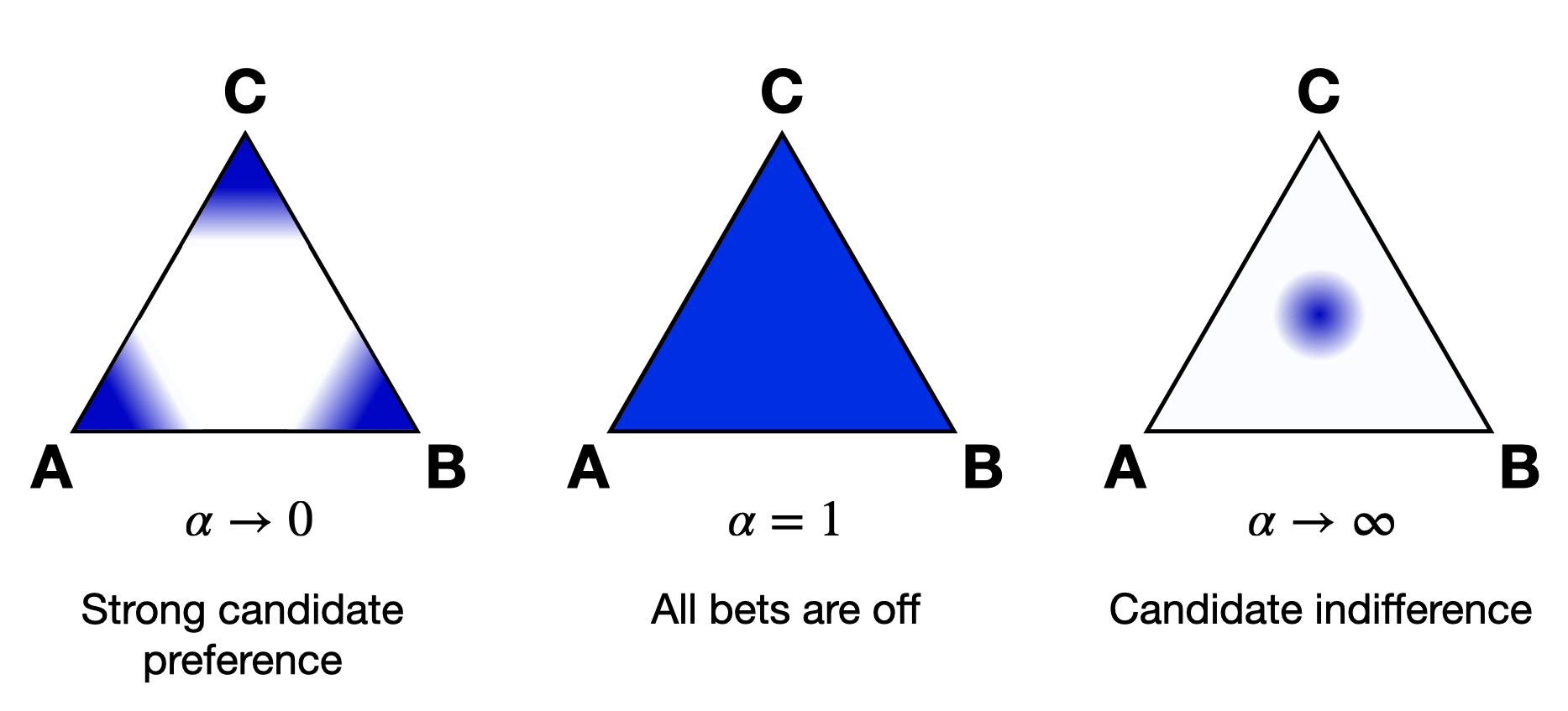
Dirichlet distributions are a one-parameter family of probability distributions on the simplex—this is used here to choose a preference interval at random. We parameterize it with a value \(\alpha \in (0,\infty)\). As \(\alpha\to \infty\), the support of the distribution moves to the center of the simplex. This means we are more likely to sample preference intervals that have roughly equal support for all candidates, which will translate to all orderings being equally likely. As \(\alpha\to 0\), the mass moves to the vertices. This means we are more likely to choose a preference interval that has strong support for a single candidate. In between is \(\alpha=1\), where any region of the simplex is weighted in proportion to its area. We think of this as the “all bets are off” setting – you might choose a balanced preference, a concentrated preference, or something in between.
The value \(\alpha\) is never allowed to equal 0 or \(\infty\) in Python, so VoteKit changes these to a very small number (\(10^{-10}\)) and a very large number \((10^{20})\). We don’t recommend using values that extreme. In previous studies, MGGG members have taken \(\alpha = 1/2\) to be “small” and \(\alpha = 2\) to be “big.”
png
It is easy to sample a PreferenceInterval from the Dirichlet
distribution. Rerun the code below several times to get a feel for how
these change with randomness.
strong_pref_interval = PreferenceInterval.from_dirichlet(
candidates=["A", "B", "C"], alpha=0.1
)
print("Strong preference for one candidate", strong_pref_interval)
abo_pref_interval = PreferenceInterval.from_dirichlet(
candidates=["A", "B", "C"], alpha=1
)
print("All bets are off preference", abo_pref_interval)
unif_pref_interval = PreferenceInterval.from_dirichlet(
candidates=["A", "B", "C"], alpha=10
)
print("Uniform preference for all candidates", unif_pref_interval)
Strong preference for one candidate {'A': np.float64(0.1409), 'B': np.float64(0.0055), 'C': np.float64(0.8537)}
All bets are off preference {'A': np.float64(0.8796), 'B': np.float64(0.0684), 'C': np.float64(0.052)}
Uniform preference for all candidates {'A': np.float64(0.3903), 'B': np.float64(0.4263), 'C': np.float64(0.1833)}
Let’s initialize the s-PL model from the Dirichlet distribution, using that to build a preference interval rather than specifying the interval. Each bloc will need two Dirichlet alpha values; one to describe their own preference interval, and another to describe their preference for the opposing candidates.
bloc_proportions = {"X": 0.8, "Y": 0.2}
# the values of .9 indicate that these blocs are highly polarized;
# they prefer their own candidates much more than the opposing slate
cohesion_mapping = {"X": {"X": 0.9, "Y": 0.1}, "Y": {"Y": 0.9, "X": 0.1}}
alphas = {"X": {"X": 2, "Y": 1}, "Y": {"X": 1, "Y": 0.5}}
slate_to_candidates = {"X": ["X1", "X2"], "Y": ["Y1", "Y2"]}
# the from_params method allows us to sample from
# the Dirichlet distribution for our intervals
config = bg.BlocSlateConfig(n_voters = 100,
bloc_proportions=bloc_proportions,
cohesion_mapping=cohesion_mapping,
slate_to_candidates=slate_to_candidates,
)
config.set_dirichlet_alphas(alphas)
print("Preference interval for X bloc and all candidates")
print(config.preference_df.loc["X"])
print()
print("Preference interval for Y bloc and all candidates")
print(config.preference_df.loc["Y"])
profile_dict = bg.slate_pl_profiles_by_bloc_generator(config)
print()
print(profile_dict["X"].df)
Preference interval for X bloc and all candidates
X1 0.811907
X2 0.188093
Y1 0.032547
Y2 0.967453
Name: X, dtype: float64
Preference interval for Y bloc and all candidates
X1 0.190813
X2 0.809187
Y1 0.970273
Y2 0.029727
Name: Y, dtype: float64
Ranking_1 Ranking_2 Ranking_3 Ranking_4 Weight Voter Set
Ballot Index
0 (X2) (X1) (Y2) (Y1) 12 {}
1 (X2) (Y2) (Y1) (X1) 1 {}
2 (X2) (Y2) (X1) (Y1) 1 {}
3 (X1) (X2) (Y2) (Y1) 49 {}
4 (X1) (X2) (Y1) (Y2) 1 {}
5 (X1) (Y2) (X2) (Y1) 9 {}
6 (Y2) (X1) (X2) (Y1) 4 {}
7 (Y2) (X2) (X1) (Y1) 2 {}
8 (Y2) (Y1) (X1) (X2) 1 {}
Let’s confirm that the intervals and ballots look reasonable. We have \(\alpha_{XX} = 2\) and \(\alpha_{XY} = 1\). This means that the \(X\) voters tend to be relatively indifferent among their own candidates, but might adopt any candidate strength behavior for the \(Y\) slate.
Try it yourself
Change the code above to check that the preference intervals and ballots for the \(Y\) bloc look reasonable.
Cambridge Sampler
We introduce one more method of generating ballots: the Cambridge Sampler (CS). CS generates ranked ballots using historical election data from Cambridge, MA (which has been continuously conducting ranked choice elections since 1941). It is the only ballot generator we will see today that is capable of producing incomplete ballots, including bullet votes.
By default, CS uses five elections (2009-2017, odd years); with the help of local organizers, we coded the candidates as White (W) or People of Color (POC, or C for short). This is not necessarily the biggest factor predicting people’s vote in Cambridge – housing policy is the biggie – but it’s a good place to find realistic rankings, with candidates of two types.
You also have the option of providing CS with your own historical election data from which to generate ballots instead of using Cambridge data.
bloc_proportions = {"W": 0.8, "C": 0.2}
# the values of .9 indicate that these blocs are highly polarized;
# they prefer their own candidates much more than the opposing slate
cohesion_mapping = {"W": {"W": 0.9, "C": 0.1}, "C": {"C": 0.9, "W": 0.1}}
alphas = {"W": {"W": 2, "C": 1}, "C": {"W": 1, "C": 0.5}}
slate_to_candidates = {"W": ["W1", "W2", "W3"], "C": ["C1", "C2"]}
config = bg.BlocSlateConfig(n_voters = 1000,
bloc_proportions=bloc_proportions,
cohesion_mapping=cohesion_mapping,
slate_to_candidates=slate_to_candidates,
)
config.set_dirichlet_alphas(alphas)
profile = bg.cambridge_profile_generator(config)
print(profile.df.head(10).to_string())
Ranking_1 Ranking_2 Ranking_3 Ranking_4 Ranking_5 Weight Voter Set
Ballot Index
0 (W1) (W3) (C1) (W2) (C2) 14.0 {}
1 (W1) (W3) (C1) (W2) (~) 7.0 {}
2 (W1) (W3) (C1) (~) (~) 12.0 {}
3 (W1) (W3) (C1) (C2) (~) 3.0 {}
4 (W1) (W3) (C1) (C2) (W2) 7.0 {}
5 (W1) (W3) (~) (~) (~) 28.0 {}
6 (W1) (W3) (W2) (C1) (C2) 25.0 {}
7 (W1) (W3) (W2) (C1) (~) 15.0 {}
8 (W1) (W3) (W2) (~) (~) 24.0 {}
9 (W1) (W3) (W2) (C2) (~) 8.0 {}
Note: the ballot type (as in, Ws and Cs) is strictly drawn from the historical frequencies. The candidate IDs (as in W1 and W2 among the W slate) are filled in by sampling without replacement from the preference interval that you either provided or made from Dirichlet alphas. That is the only role of the preference interval.
Conclusion
There are many other models of ballot generation in VoteKit, both for ranked choice ballots and score based ballots (think cumulative or approval voting). See the ballot generator section of the VoteKit documentation for more.